AlexNet 模型
AlexNet 模型是什么?
AlexNet 是由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 在 2012 年提出的深度卷积神经网络。它在 2012 年 ImageNet 大规模视觉识别挑战赛(ILSVRC)上取得了突破性的成果,大大超越了当时的其他方法,从而引发了深度学习在计算机视觉领域的热潮。
AlexNet 是一个深度卷积神经网络,它的结构如下:
输入层:
- 输入图像的尺寸为 227x227x3(原始论文中提到的是 224x224,但实际上由于卷积核大小和步长的设置,输入尺寸应为 227x227)。
第一层 (C1):
- 卷积层:使用 96 个 11x11 的卷积核,步长为 4,不使用填充。
- 激活函数:ReLU。
- 局部响应归一化 (LRN)。
- 最大池化:使用 3x3 的核,步长为 2。
第二层 (C2):
- 卷积层:使用 256 个 5x5 的卷积核,步长为 1,使用 2 的填充。
- 激活函数:ReLU。
- 局部响应归一化 (LRN)。
- 最大池化:使用 3x3 的核,步长为 2。
第三层 (C3):
- 卷积层:使用 384 个 3x3 的卷积核,步长为 1,使用 1 的填充。
- 激活函数:ReLU。
第四层 (C4):
- 卷积层:使用 384 个 3x3 的卷积核,步长为 1,使用 1 的填充。
- 激活函数:ReLU。
第五层 (C5):
- 卷积层:使用 256 个 3x3 的卷积核,步长为 1,使用 1 的填充。
- 激活函数:ReLU。
- 最大池化:使用 3x3 的核,步长为 2。
第六层 (F6):
- 全连接层:有 4096 个神经元。
- 激活函数:ReLU。
- Dropout:为了减少过拟合,训练时随机丢弃一半的神经元。
第七层 (F7):
- 全连接层:有 4096 个神经元。
- 激活函数:ReLU。
- Dropout:同上。
输出层 (F8):
- 全连接层:有 1000 个神经元,对应于 ImageNet 数据集的 1000 个类别。
- 激活函数:Softmax,用于分类概率输出。
此外,AlexNet 在两个 GPU 上并行训练,其中某些层是在两个 GPU 之间分割的。这是由于当时的 GPU 内存限制。
这种深度和宽度的结合,以及上述提到的一些关键技术(如 ReLU、Dropout 和 LRN),使 AlexNet 能够在 ImageNet 挑战赛上取得突破性的成果。

AlexNet 主要特点:
- 更深的网络结构:AlexNet 由 5 个卷积层、3 个全连接层和最后的 Softmax 分类层组成。
- ReLU 激活函数:AlexNet 是第一个大规模使用 ReLU(Rectified Linear Unit)作为激活函数的网络,这加速了训练过程。
- Dropout:为了减少过拟合,AlexNet 在全连接层中使用了 Dropout。
- 局部响应归一化(LRN):在某些卷积层后使用了局部响应归一化,但后来的研究发现这并不是必要的。
- 数据增强:为了进一步减少过拟合,AlexNet 使用了图像平移、翻转和颜色变化等数据增强技术。
- 双 GPU 训练:由于当时的 GPU 计算能力有限,AlexNet 在两个 GPU 上并行训练。
与 LeNet 的区别:
- 深度:AlexNet 比 LeNet 深得多,有更多的卷积层和全连接层。
- 参数数量:由于其深度和宽度,AlexNet 有比 LeNet 多得多的参数。
- 激活函数:AlexNet 使用 ReLU 作为激活函数,而 LeNet 通常使用 Sigmoid 或 Tanh。
- 正则化:AlexNet 使用 Dropout 和数据增强来减少过拟合,而原始的 LeNet 没有使用这些技术。
- 归一化:AlexNet 使用了局部响应归一化,而 LeNet 没有。
- 计算需求:由于其深度和宽度,AlexNet 的计算需求比 LeNet 大得多。
尽管 AlexNet 和 LeNet 都是卷积神经网络,但 AlexNet 在结构、深度、宽度和训练技术上都有很大的改进。这些改进使 AlexNet 能够在大规模图像数据集上取得出色的性能,从而标志着深度学习在计算机视觉领域的崛起。
PyTorch 实现的 AlexNet 模型
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
# 第一层 (C1)
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.LocalResponseNorm(5, alpha=0.0001, beta=0.75, k=2), # LRN
# 第二层 (C2)
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.LocalResponseNorm(5, alpha=0.0001, beta=0.75, k=2), # LRN
# 第三层 (C3)
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# 第四层 (C4)
nn.Conv2d(384, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# 第五层 (C5)
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
# 全连接层
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
# 创建一个 AlexNet 实例
model = AlexNet(num_classes=1000)
训练 Fashion-MNIST 数据集
注意 Fashion-MNIST 数据集的大小是 28*28 的图片,而原版的 AlexNet 面向的是更大 ImageNet 数据集的图片,所以这里的卷积层会比较大,请这里需要处理一下 Fashion-MNIST 数据集的图片大小,可以适当的放大
首先,我们需要对 Fashion-MNIST 数据集的图片进行放大,使其适应 AlexNet 的输入尺寸。我们可以使用 torchvision.transforms 中的 Resize 函数来实现这一点。接下来,我们将定义一个适应 Fashion-MNIST 数据集的 AlexNet 模型,并进行训练。
以下是完整的代码:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# 数据加载和预处理
transform = transforms.Compose([
transforms.Resize((227, 227)), # 放大图片到 227x227
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
trainset = torchvision.datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testset = torchvision.datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False)
# 定义 AlexNet 模型
class AlexNet(nn.Module):
def __init__(self, num_classes=10): # 注意:Fashion-MNIST 有 10 个类别
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=2), # 输入通道为 1,因为 Fashion-MNIST 是灰度图
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
model = AlexNet()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {running_loss/len(trainloader)}")
print("Finished Training")
# 评估模型
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy on test set: {100 * correct / total}%")
注意:由于 AlexNet 是一个相对较大的模型,而 Fashion-MNIST 是一个相对较小的数据集,可能会出现过拟合的情况。为了获得更好的性能,可能需要进行更多的调整,如增加数据增强、调整学习率或使用预训练的模型。
变换函数说明
上面的代码中,我们使用了以下变换函数对 Fashion-MNIST 数据集进行了预处理:
transform = transforms.Compose([
transforms.Resize((227, 227)), # 放大图片到 227x227
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
变换函数是 PyTorch 中 torchvision.transforms 模块的一部分,它们用于图像的预处理。
transforms.ToTensor():- 这个变换将 PIL 图像或
numpy.ndarray转换为 PyTorch 的张量 (torch.Tensor)。 - 它会自动将图像数据从 [0, 255] 的整数范围缩放到 [0.0, 1.0] 的浮点范围。
- 对于彩色图像,它还会将图像从 HxWxC (高x宽x通道) 的形状转换为 CxHxW 的形状,以适应 PyTorch 的张量格式。
- 这个变换将 PIL 图像或
transforms.Normalize(mean, std):- 这个变换用于对图像数据进行归一化。
mean和std参数分别是每个通道的均值和标准差。在这种情况下,我们只有一个通道(因为 Fashion-MNIST 是灰度图像),所以我们只提供一个均值和一个标准差。- 归一化的计算公式为:
normalized_data = (data - mean) / std - 在这个例子中,由于我们使用
(0.5, )作为均值和标准差,归一化将把数据从 [0.0, 1.0] 的范围转换为 [-1.0, 1.0] 的范围。
归一化图像数据通常有助于模型的训练,因为它确保了数据在所有通道和数据点上都有相似的尺度。这可以帮助梯度下降算法更快地收敛,并可能提高模型的最终性能。
只取部分数据进行训练
完整的使用数据集进行训练太慢了,下面学习如何只取部分数据进行训练
可以通过 torch.utils.data.random_split 函数来随机分割数据集,并只使用其中的一小部分进行训练。以下是如何实现这一点的示例:
- 使用
random_split函数将trainset分割为一个小的子集和一个未使用的子集。 - 使用新的小子集创建
trainloader。
以下是修改后的代码:
# ... [其他代码保持不变]
# 数据加载和预处理
# ... [其他代码保持不变]
# 只使用训练集的 10% 进行训练
num_samples = len(trainset)
num_train = int(0.10 * num_samples)
subset_trainset, _ = torch.utils.data.random_split(trainset, [num_train, num_samples - num_train])
trainloader = torch.utils.data.DataLoader(subset_trainset, batch_size=64, shuffle=True)
# ... [后续代码保持不变]
在上述代码中,我们只使用了 trainset 的 10% 进行训练。您可以根据需要调整这个百分比。这样,训练过程会快得多,但请注意,由于使用的数据较少,模型的性能可能会受到影响。
使用图像展示 testAccu 和 trainLoss
这个 Accu 是指 accuracy
testAccu 和 trainLoss 是两个常用的指标,用于评估和监控机器学习模型的性能。它们分别代表以下内容:
trainLoss(训练损失):trainLoss表示模型在训练数据上的损失值。损失函数(或目标函数、成本函数)量化了模型预测与真实标签之间的差异。损失值越低,说明模型在训练数据上的表现越好。- 在训练过程中,我们的目标是最小化这个损失值,这意味着模型的预测越来越接近真实的标签。
- 但是,仅仅依赖于训练损失可能会导致过拟合,即模型在训练数据上表现得很好,但在未见过的数据上表现得不好。
testAccu(测试准确率):testAccu表示模型在测试数据(或验证数据)上的准确率。它是正确预测的样本数与总样本数的比例。- 准确率的值在 0 到 100 之间,值越高表示模型的性能越好。
- 通过监控测试准确率,我们可以评估模型在未见过的数据上的泛化能力。这有助于我们检测模型是否过拟合或欠拟合。
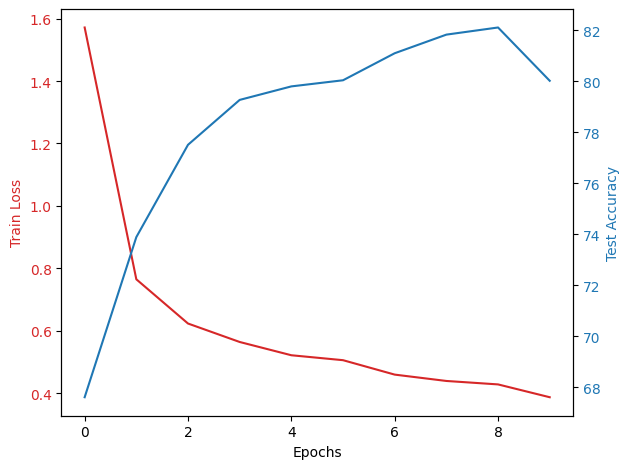
trainLoss 和 testAccu 是评估模型性能的两个重要指标。在训练过程中,我们希望看到 trainLoss 逐渐减小,而 testAccu 逐渐增加。这意味着模型正在学习,并且在测试数据上的性能也在提高。
要绘制 testAccu 和 trainLoss 的曲线,我们首先需要在训练循环中收集这些数据。然后,我们可以使用 matplotlib 来绘制这些数据。
以下是如何实现这一点的代码:
import matplotlib.pyplot as plt
# ... [其他代码保持不变]
train_losses = []
test_accuracies = []
# 训练模型
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_losses.append(running_loss/len(trainloader))
# 在每个 epoch 结束后计算测试集的准确率
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_accuracies.append(100 * correct / total)
print(f"Epoch {epoch+1}, Loss: {running_loss/len(trainloader)}, Test Accuracy: {100 * correct / total}%")
# 绘制 trainLoss 和 testAccu
fig, ax1 = plt.subplots()
color = 'tab:red'
ax1.set_xlabel('Epochs')
ax1.set_ylabel('Train Loss', color=color)
ax1.plot(train_losses, color=color)
ax1.tick_params(axis='y', labelcolor=color)
ax2 = ax1.twinx()
color = 'tab:blue'
ax2.set_ylabel('Test Accuracy', color=color)
ax2.plot(test_accuracies, color=color)
ax2.tick_params(axis='y', labelcolor=color)
fig.tight_layout()
plt.show()
在上述代码中,我们在每个 epoch 结束后都计算了训练损失和测试集的准确率,并将它们存储在 train_losses 和 test_accuracies 列表中。然后,我们使用 matplotlib 来绘制这两个指标。我们使用了双 y 轴图,其中 trainLoss 使用红色表示,testAccu 使用蓝色表示。
完整的代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
if torch.cuda.is_available():
print("CUDA (GPU support) is available and PyTorch can use GPUs!")
else:
print("CUDA is not available. PyTorch will use CPU.")
# 检查 CUDA 是否可用并定义设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 数据加载和预处理
transform = transforms.Compose([
transforms.Resize((227, 227)), # 放大图片到 227x227
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
trainset = torchvision.datasets.FashionMNIST(
root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=64, shuffle=True)
testset = torchvision.datasets.FashionMNIST(
root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False)
# 只使用训练集的 10% 进行训练
num_samples = len(trainset)
num_train = int(0.10 * num_samples)
subset_trainset, _ = torch.utils.data.random_split(trainset, [num_train, num_samples - num_train])
trainloader = torch.utils.data.DataLoader(subset_trainset, batch_size=64, shuffle=True)
# 定义 AlexNet 模型
class AlexNet(nn.Module):
def __init__(self, num_classes=10): # 注意:Fashion-MNIST 有 10 个类别
super(AlexNet, self).__init__()
self.features = nn.Sequential(
# 输入通道为 1,因为 Fashion-MNIST 是灰度图
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
model = AlexNet().to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
train_losses = []
test_accuracies = []
# 训练模型
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_losses.append(running_loss/len(trainloader))
# 在每个 epoch 结束后计算测试集的准确率
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_accuracies.append(100 * correct / total)
print(f"Epoch {epoch+1}, Loss: {running_loss/len(trainloader)}, Test Accuracy: {100 * correct / total}%")
# 绘制 trainLoss 和 testAccu
fig, ax1 = plt.subplots()
color = 'tab:red'
ax1.set_xlabel('Epochs')
ax1.set_ylabel('Train Loss', color=color)
ax1.plot(train_losses, color=color)
ax1.tick_params(axis='y', labelcolor=color)
ax2 = ax1.twinx()
color = 'tab:blue'
ax2.set_ylabel('Test Accuracy', color=color)
ax2.plot(test_accuracies, color=color)
ax2.tick_params(axis='y', labelcolor=color)
fig.tight_layout()
plt.show()
print("Finished Training")
# 评估模型
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy on test set: {100 * correct / total}%")
输出
CUDA (GPU support) is available and PyTorch can use GPUs!
Epoch 1, Loss: 1.5718631782430283, Test Accuracy: 67.61%
Epoch 2, Loss: 0.7645940660162175, Test Accuracy: 73.89%
Epoch 3, Loss: 0.6227985303452674, Test Accuracy: 77.51%
Epoch 4, Loss: 0.5636293846876064, Test Accuracy: 79.27%
Epoch 5, Loss: 0.521078274605122, Test Accuracy: 79.8%
Epoch 6, Loss: 0.5052669828242444, Test Accuracy: 80.04%
Epoch 7, Loss: 0.4590177811840747, Test Accuracy: 81.1%
Epoch 8, Loss: 0.43865276096349065, Test Accuracy: 81.83%
Epoch 9, Loss: 0.42760626876607855, Test Accuracy: 82.11%
Epoch 10, Loss: 0.38648864832964347, Test Accuracy: 80.02%
Finished Training
Accuracy on test set: 80.55%